

Analytics is on the rise, and we’re betting the farm on it. Let’s talk about how analytics has evolved over the last decade, and why I believe analysts need a new tool.
The tl;dr: analytics is changing, and our tooling must change with it.
Less than a decade ago, analytics used to be about showing data to people. It was about constructing cubes, making dashboards, all towards a simple yet, at the time, cumbersome charter: rudimentary visibility into core metrics. Our scope was limited in that way, but not by choice — we were hamstrung by the limitations of our tools: data was slow to access and manipulate, so we couldn’t uncover insights without loading slices of data into memory with Jupyter, and robust data modeling required developer-level familiarity with high-barrier-to-entry tools like cron or Airflow. Many of us ended up being pulled into data science, because that’s the only place where we could do proper analytics work. Others of us pursued data engineering, because that’s where everything was breaking. And the most opportunistic of us jumped the fence to the business side of things, because that’s where the influence was.
Around 2017, two big things started to change:
The two biggest hurdles in analytics were solved: getting clean data and accessing it. And suddenly we went from a world where data access was privileged to one where data became a commodity. The conversation shifted from: how many analysts do we need to build a dashboard to how do we get more value out of data?
If data is the new oil, the warehouse + MDS were like the first oil wells — but we needed to refine all that oil. Naturally, we let our processes here adapt organically: we fielded more ad hoc questions, we offered our help in more strategic discussions, we sparked company-wide initiatives that pushed for self-service, we hired cohorts of new analysts.
But the patterns we naturally fell into were not good. We responded to questions with data. We proactively built more dashboards with wider self-service capabilities. We got good at pulling data, so they asked us for more data. We became data librarians, not thought partners. We over-hired analytics engineers, believing that more data correlated directly with more impact.
Lately, things have started to change. Some cocktail of semantic layer, chatGPT, and self-service advances are soon going to make mass market self-service for a large number of basic questions a reality. The days of training stakeholders to make Looker explores will soon be over.
But over the next few years, we’re going to collectively realize that there’s a limit to self-service. For once all self-serviceable questions are answered, only non-self-serviceable requests will remain. And a rich world of business-savvy analytics lays on the horizon.
And this is where our story begins.
It's in these non-self-serviceable questions where our principle pains both have proliferated and will continue to proliferate. The reactivity, the chaos and poor standardization of work, the brokenness of our stakeholder relationships — these will only get worse as more of our time is spent doing more custom work. And at first glance, it seems like there are many reasons for this state of affairs: process problems, structural problems, mindset problems.
But while many of these certainly need to be fixed, all roads also point to a single, fundamental problem: we’re missing critical tooling. We have tools that address our technical needs, but we're missing tools that match our workflow needs — collaborating with stakeholders, writing up work, sharing work, centralizing analyses. We have point solutions that make it harder to do things right, and so we do nothing right. We leave our SQL queries in IDE tabs, we deliver data devoid of interpretation, and our business counterparts stay as stakeholders and recipients, not collaborators.
Just as data scientists get Jupyter and data engineers get the IDE, analysts deserves a tool purpose-built for analyses, not something riddled with historical baggage and vestigial design patterns. We need a tool that’s:
And with that, we’re announcing our public beta. Hyperquery is the world’s first data notebook built from the ground up for analytics, and every product decision has been made with analytics in mind.
Hyperquery is not only delightfully fast, perfect for your day-to-day work..
… but also seamlessly shareable and centralized.
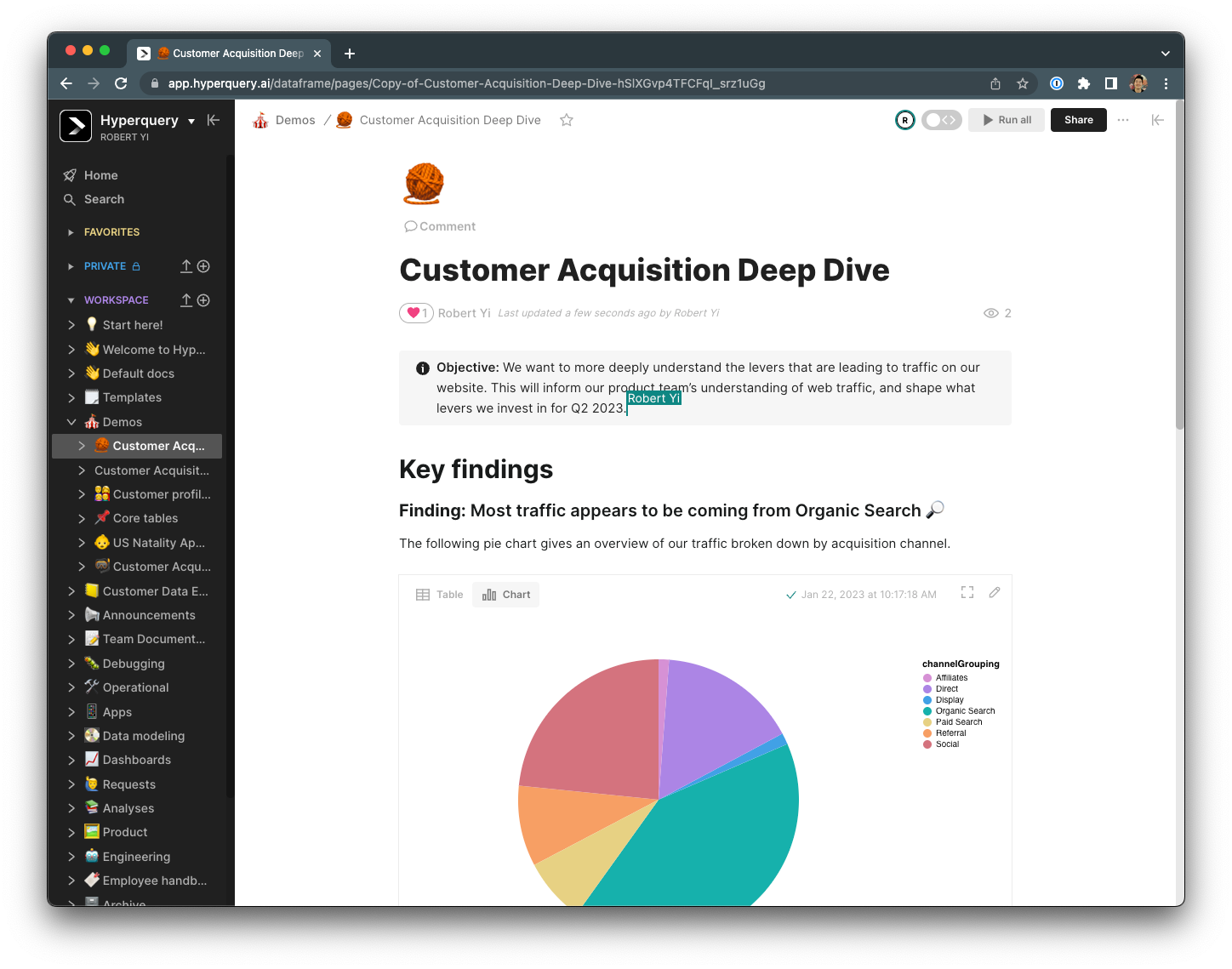
Unlike other tools, you’ll be nudged towards good habits — writing work and organizing it. Unlike other tools, your stakeholders will actually work with you in Hyperquery, not just passively consume your work. And unlike other tools, you don’t have to spend a lot of time crafting something presentable.
After building in private for more than a year, we’re finally coming out to the public — hundreds of teams have started using us, and we’re currently the number #1 product in Data and Analytics on Product Hunt. Try us out at hyperquery.ai. 🙂
Analytics is changing, so tooling must change as well.
Alright, blatant ad over. Tune in again next week for your regularly scheduled Win With Data programming.
Tweet @imrobertyi / @hyperquery to say hi.👋
Follow us on LinkedIn. 🙂
To learn more about hyperquery, visit hyperquery.ai.






